TimeSeries

1
2
3
4
5
6
7
8
9
<목차>
0. 시작하며
1. TimeSeries 개념
2. 웹 유입량 분석
2-1) pinkwink 불러오기
2-2) 원데이터 그래프 확인
2-3) trend 분석을 위한 그래프
3. Prophet 활용한 시계열 분석
0. 시작하며
이글은 제로베이스 데이터스쿨 강의를 듣고 작성했습니다.
이번 시간은 Timeseries Analysis에 대해 간략히 알아보고
pinkwink 웹사이트의 조회수 분석에 대한 시계열 분석 실습을 진행해보겠습니다.
1. TimeSeries 개념
시계열 데이터란?
시간의 흐름에 대해 특정 패턴과 같은정보를 가진 자료
시계열 예측에 좋은 모듈: Prophet
ex) 주식
아래는 시계열에 대한 이해도를 돕기위한 간략한 삽화입니다
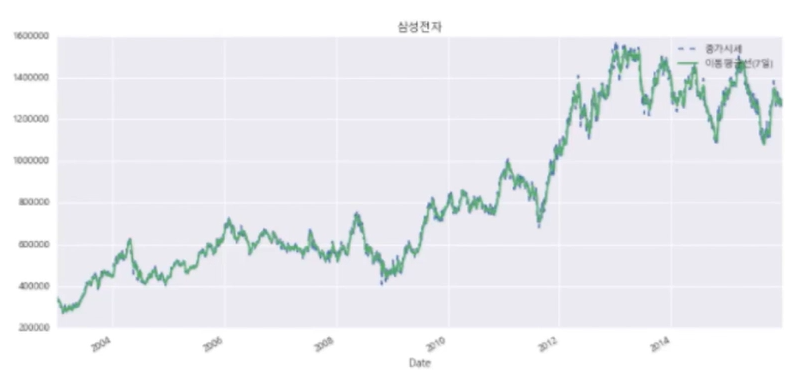
만약 위와 같은 데이터를 분석하고 싶다면 아래와 같은 트렌드를 찾아야 합니다

이것은 트렌드입니다. 이제 원데이터 - 트렌드 를 하면 아래와 같은 주기적 특성이 나옵니다

이게 우리가 찾고자했던 패턴입니다.
2. 웹 유입량 분석
PinkWink 사이트에 대해 살펴보겠습니다
참고
원래 fbprophet이라고 설치하고 import도 fbprophet이었는데 현재는 prophet으로 바뀌었습니다.
그래서 설치할때도, import 할 때에도 fbprophet이 아닌 prophet으로 적어야 합니다.
1
2
3
4
5
6
7
시작하기 전에 저는 먼저 아래 경로에서 Prophet을 설치했습니다
# 경로
C:\Users\withj\Desktop\python1\Lib\site-packages>
# 모듈 설치
pip install Prophet
2-1) pinkwink 불러오기
베이스 코드
1
2
3
4
5
6
7
import pandas as pd
import pandas_datareader as web
import numpy as np
import matplotlib.pyplot as plt
from prophet import Prophet
from datetime import datetime
src = "C:/Users/withj/Desktop/eda-practice/time"
pinkwink 클릭 수 불러오기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
pinkwink_web = pd.read_csv(
src+ "/pinkwink_web_traffic.csv",
encoding="utf-8",
thousands=",",
# 컬럼명
names=["date", "hit"],
# 첫번째 열을 인덱스로 사용
index_col=0
)
# hit 컬럼에서 nan 열이 아닌 행만 남음
pinkwink_web = pinkwink_web[pinkwink_web["hit"].notnull()]
pinkwink_web.head()
잠깐!! 이거 되게 기초적인 내용인데 참고하면 좋을 것 같습니다
1번째 사진은 그냥 csv만 불러온 것
2번째 사진은 컬럼 추가
아까 위에 사진은 첫 번째 열을 인덱스로 사용
2-2) 원데이터 그래프 확인
1
2
# 전체 데이터 그려보기
pinkwink_web["hit"].plot(figsize=(12, 4), grid=True);
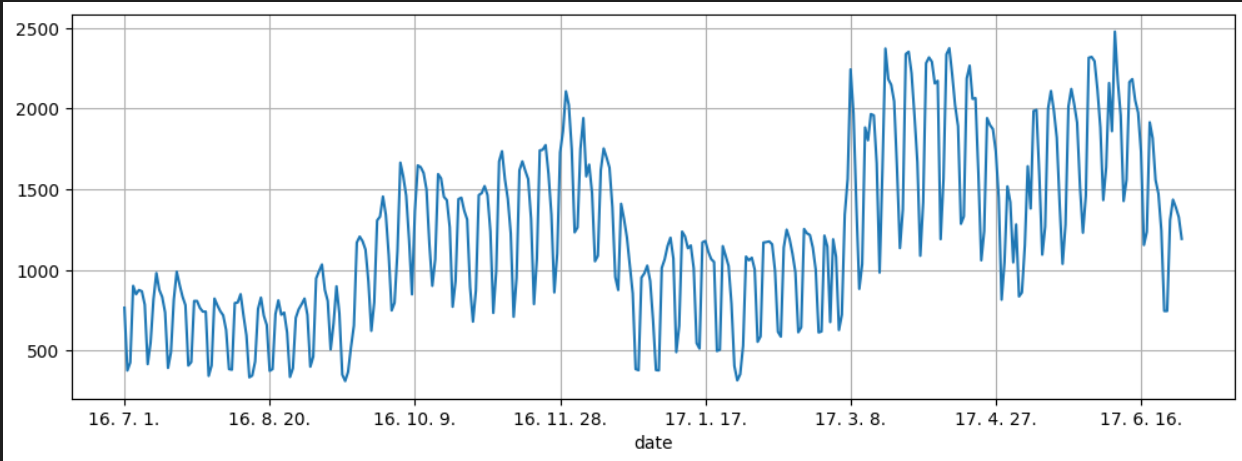
위는 pinkwink 홈페이지의 2016.07 ~ 2017.06 까지의 방문객 수를 나타내는 그래프입니다
그래프를 보니 다양한 주기성 보이네요. 아래는 그 주기들 중 2개입니다
2-3) trend 분석을 위한 그래프
1
2
3
4
# trend 분석을 시각화하기 위한 x축 값을 만들기
time = np.arange(0, len(pinkwink_web))
traffic = pinkwink_web["hit"].values
fx = np.linspace(0, time[-1], 1000)
x축을 만들기 위해 아래 조건 부여해주었습니다.
- 원 데이터의 총 길이를 time으로
- traffic을 hit의 값만 추출
- 0부터 time의 마지막원소까지 1000등분
1
2
3
4
# 에러를 계산할 함수
# f(x)는 예측값, y는 참값
def error(f, x, y):
return np.sqrt(np.mean((f(x) - y) ** 2))
error함수:
trend분석을 위해 만든게 원데이터를 잘 반영하는지에 대한 수치적 평가지표입니다
에러**2에 루트를 씌운 것으로, RMSE랑 모양틀이 같습니다
\(\text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}\)
다차항함수 만들기
각각 time과 traffic을 받아 1, 2, 3, 15차 함수를 만들어 보겠습니다.
결과적으로 f1, f2, f3, f15라는 함수가 만들어졌습니다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
fp1 = np.polyfit(time, traffic, 1)
f1 = np.poly1d(fp1)
f2p = np.polyfit(time, traffic, 2)
f2 = np.poly1d(f2p)
f3p = np.polyfit(time, traffic, 3)
f3 = np.poly1d(f3p)
f15p = np.polyfit(time, traffic, 15)
f15 = np.poly1d(f15p)
print(error(f1, time, traffic))
print(error(f2, time, traffic))
print(error(f3, time, traffic))
print(error(f15, time, traffic))
#➡️ 430.8597308110963
#➡️ 430.6284101894695
#➡️ 429.5328046676293
#➡️ 330.47773023519215
1, 2, 3차 함수까지 에러는 큰 차이가 없습니다.
그런데 15차 함수를 보니 변화가 좀 큽니다.
이런 경우에는 계수가 적은 1차함수를 선택하거나 혹은 15차 함수를 선택하여 그래프를 확인하는게 낫겠습니다.
일단 전부 다 그려보겠습니다
1
2
3
4
5
6
7
8
9
10
plt.figure(figsize=(12, 4))
plt.scatter(time, traffic, s=10)
plt.plot(fx, f1(fx), lw=4, label='f1')
plt.plot(fx, f2(fx), lw=4, label='f2')
plt.plot(fx, f3(fx), lw=4, label='f3')
plt.plot(fx, f15(fx), lw=4, label='f15')
plt.grid(True, linestyle="-", color="0.75")
plt.legend(loc=2)
plt.show()
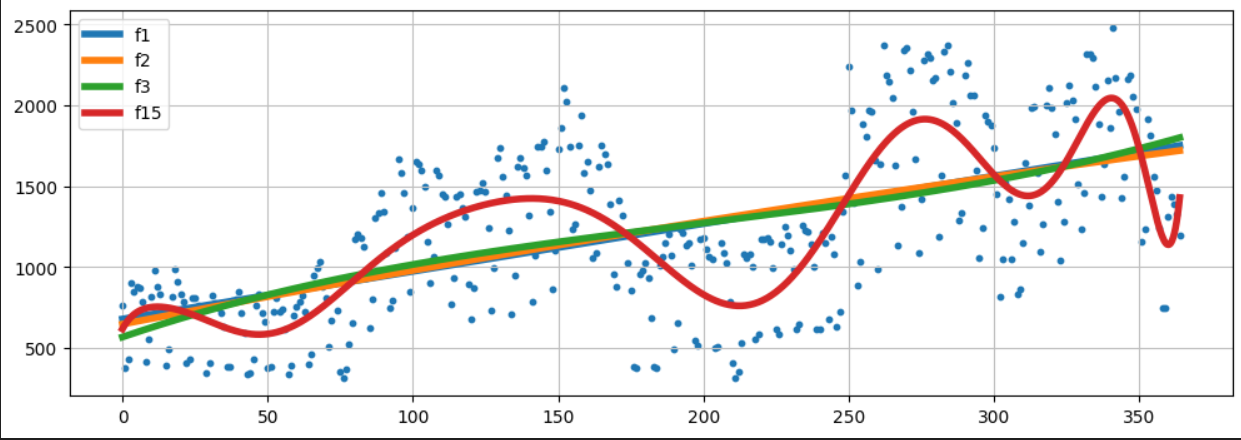
그래프를 보면 우선 파란색 점이 원 데이터고 아까 위에서 말했듯이 1, 2, 3차함수보다 15차함수가 원데이터에 조금 더 정확하긴한데 어떤 함수를 트렌드로 판단할지는 디자이너의 몫입니다.
우선 저라면 계수가 제일 낮은 1차함수를 선택하겠습니다.
그 이유는 계산하기 편하여 예측하는데 사용하기에 제일 좋을 것 같네요
일단 여기까지는 numpy를 적용하여 실습한 것이고 아래부터 Prophet 함수를 적용하여 보겠습니다
3. Prophet 활용한 시계열 분석
1
2
3
4
5
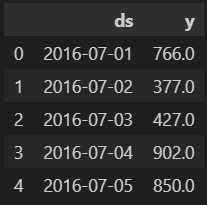
df = pd.DataFrame({"ds": pinkwink_web.index, "y": pinkwink_web["hit"]})
df.reset_index(inplace=True)
df["ds"] = pd.to_datetime(df["ds"], format="%y. %m. %d.")
del df["date"]
df.head()
1
2
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
시계열 모듈에 연간계절성O, 일일계절성O
아까 위에 정의한 df를 m에 학습시킵니다.
앞으로 60일 뒤의 데이터를 예측하도록 시켰습니다.
1
2
3
# 60일에 해당하는 데이터 예측
future = m.make_future_dataframe(periods=60)
future.tail()
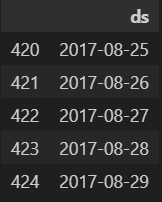
이제 이에 해당하는 결과를 뽑아보겠습니다
1
2
3
# 예측 결과는 상한/하한의 범위를 포함해서 얻어진다
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()
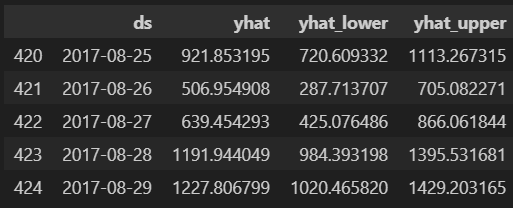
위의 표를 보면 날짜별 모델의 예측값과, 예측값 하한선, 상한선을 알 수 있습니다.
그래프로 보겠습니다
1
m.plot(forecast);
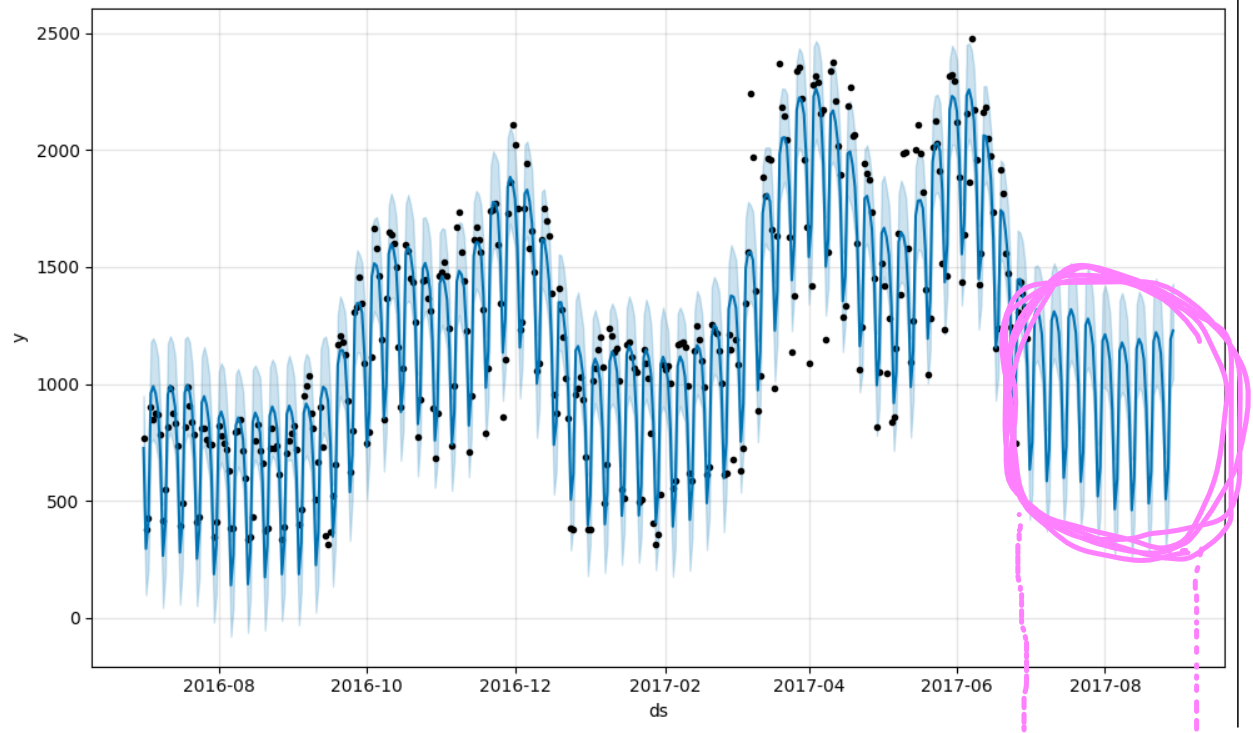
오오! 그래프를 보면 6월 16일 이후로 8월의 딱 일부구간까지 예측하여 생성한 구간이 보일겁니다!
참고로 시계열 모델에 제공한 데이터를 fit할 때, 데이터의 주기성이 좋을수록 예측결과가 좋아집니다
trend 분석
plot_components()를 쓰면 시계열로 예측한 그래프를 볼 수 있습니다
1
m.plot_components(forecast);
그래프가 한번에 4개 나오는데 각각 설명을 위해 한개씩 보겠습니다.
1. 트렌드
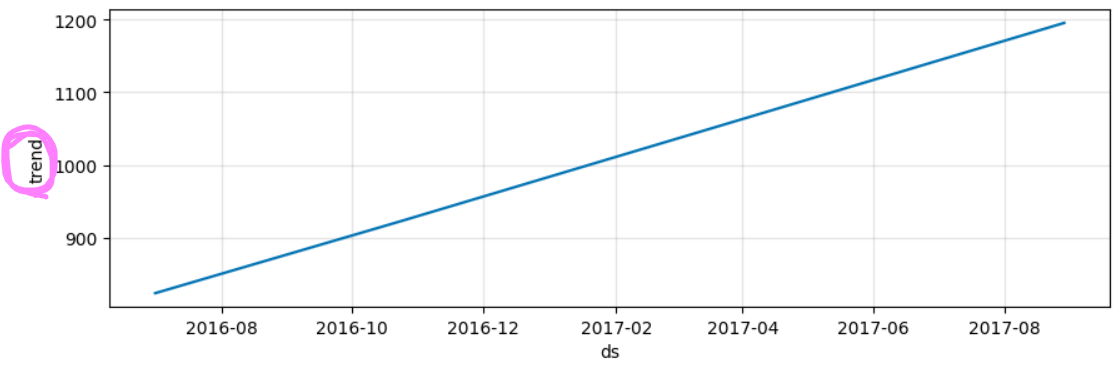
아까 Prophet 함수를 쓰기 전에 numpy로 썼을 때 1차함수가 제일 좋을 것 같다고 했는데
역시나 Prophet함수가 trend 예측을 1차함수로 해줬습니다!
2. 요일별 특성
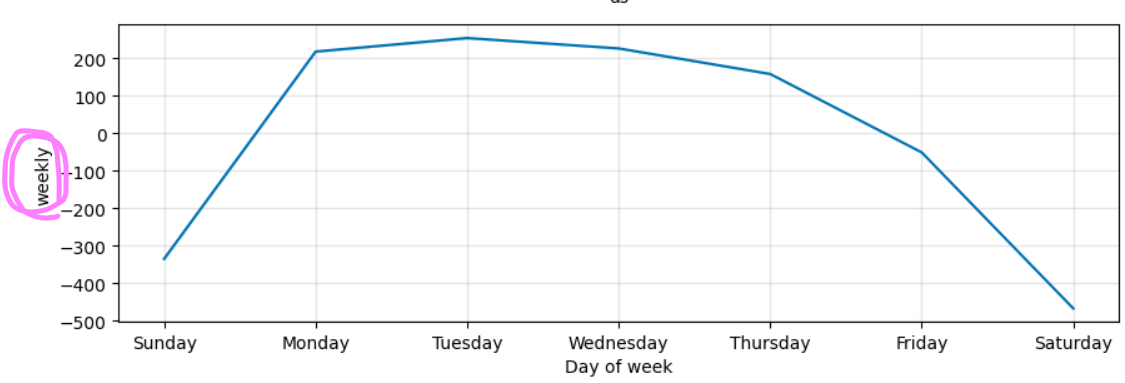
pinkwink 웹사이트에서 일주일 중에 월, 화, 수가 방문객이 많네요!
3. 월별 특성
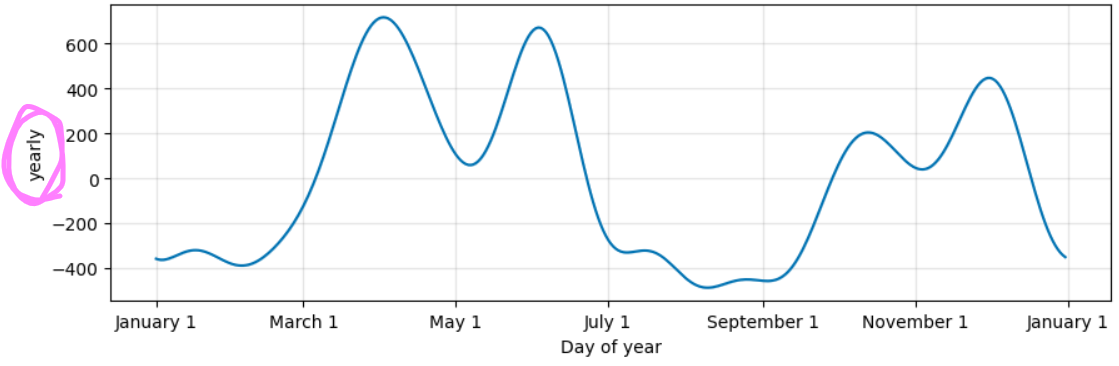
어??? 왜 4월~6월이랑 10월 ~ 12월에 조회수가 많을까?
why? —> 그건 pinkwink가 학습플랫폼이라서 교수님이 중간&기말고사에 관한 학습자료를 많이 올려놓으셨기에 4~6, 10~12월에 학생들 조회수가 폭발적으로 증가할 수 밖에 없었던 것입니다.
4. 24시간 내 특성
이 그래프는 큰 의미가 없습니다. 왜냐하면 저희가 데이터를 하루에 1개만 주었기 때문입니다.
이상으로 pinkwink를 시계열분석으로 실습해본 것을 마치겠습니다.
여기까지 읽어주신 분들 감사합니다.

